ABBYY FlexiCapture는 종이 서류에 있는 문자 정보를 높은 정밀도로 인식하고 필요한 정보만을 추출해 데이터화 할 수있는 지능형 플랫폼입니다.
다국어 지원 및 AI 학습 기능도 탑재되어, 고객의 비용 절감, 신속 · 효율적인 비즈니스를 서포트합니다.
Business Support Tools ABBYY FlexiCapture
모든 형태의 정보를 현명하게 추출 업무 프로세스를 스마트하게

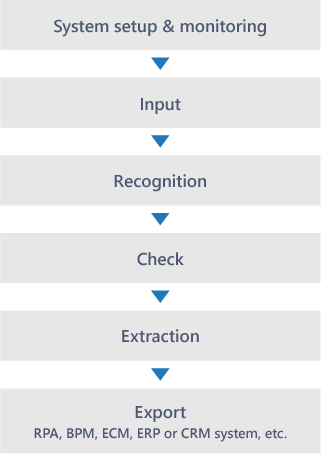
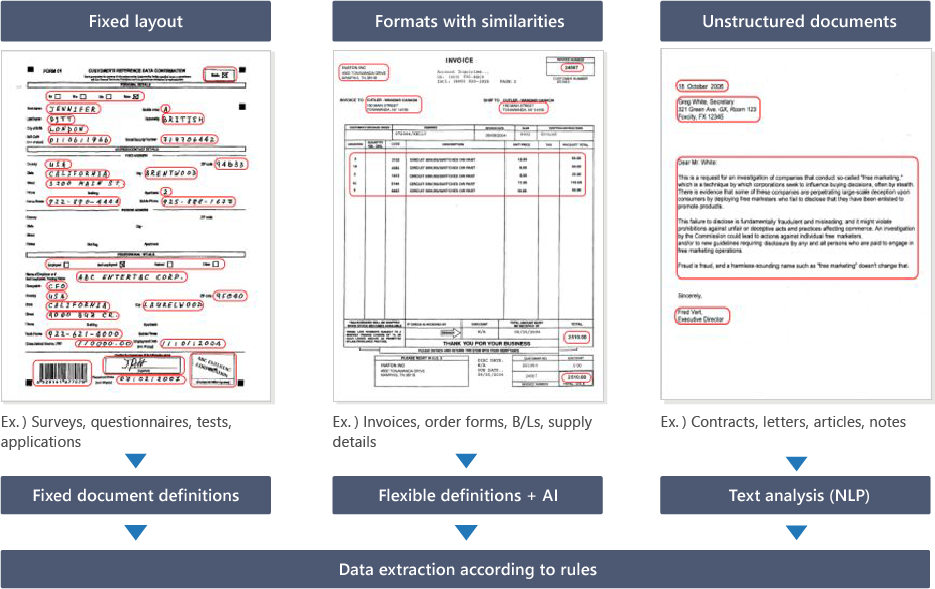
모든 종류의 문서를 지원합니다.
규칙을 정의하고 필요한 데이터를 추출합니다.
휴대 기기, 이메일, 팩스, 문서 스캐너, FTP, 다기능 프린터 등 모든 데이터 소스 콘텐츠의 처리를 지원합니다.
문서의 분류 · 데이터 추출 작업은 AI에 의해 자동화됩니다.
관리자는 AI의 작업 결과를 편집할 수 있기 때문에 완전한 컨트롤이 유지됩니다.
전표의 헤더 항목과 명세 내역의 추출 등, 규칙을 유연하게 정의해 필요한 데이터를 추출 할 수 있습니다.
RPA 제품과의 유연한 연계가 가능합니다.
더 스마트하게 효율화를 실현합니다.
처리된 데이터는 RPA · ERP 및 CRM 시스템 등 외부 어플리케이션에서 사용할 수 있습니다.
자동화를 통해 업무를 효율화하는 RPA와 연계 함으로써 지금까지 수작업에 의존했던 종이 서류의 정보 추출에서 시스템 입력까지 자동화가 가능합니다.
ABBYY FlexiCapture는 UiPath 등의 RPA 제품의 커넥터를 사용할 수 있습니다. 문서의 분류 및 데이터 추출 후, 결과를 RPA에 반영합니다.
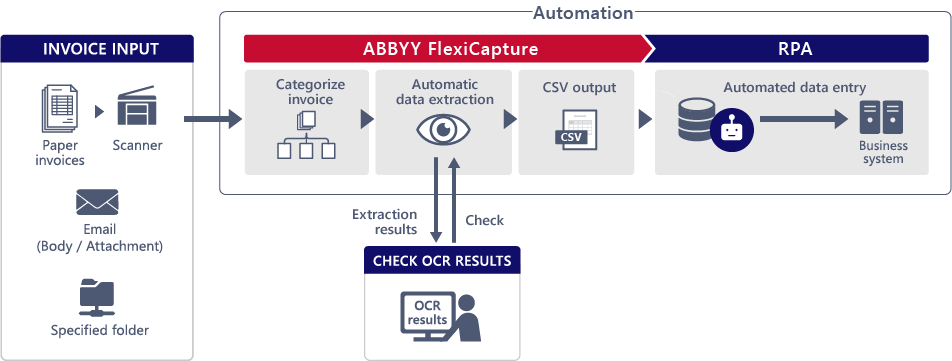
적용 예 : 청구서 입력 업무의 자동화 (ABBYY FlexiCapture + RPA)
형식이 각기 다른 청구서를 분석하여 자동으로 분류 · 문자 인식 (OCR)를 실시해, 거래처, 청구서번호, 청구날짜 등의 입력에 필요한 정보를 자동 추출.
담당자는 OCR 결과를 확인하는 것만으로, 기간 시스템 입력을 RPA 소프트웨어가 자동으로 처리.
유연한 워크 플로우 커스터마이즈 기능
스캔 및 문서의 분류, 인식과 추출 타사 OCR /ICR 엔진의 이용, 새로운 검증 및 데이터 내보내기 등 요구에 유연하게 맞출 수 있습니다
독립형 / distributed형
소규모 프로젝트의 시스템 설정부터 데이터 추출, 내보내기까지 모두 하나의 시스템에서 완결 할 수있는(독립형 설치), 역할을 여러 PC에 분산한 대규모 OCR 프로젝트에 대응 할 수 있는(distributed형 설치) 2 종류가 준비되어 있습니다.
고급 권한 관리
사내와 외주 등 다른 액세스 권한자 간의 작업을 지원하고 기밀 데이터를 보호합니다.
성능
대량의 문서도 고속 처리가 가능합니다.
1개월 당 10,000 페이지 이상을 처리 할 수 있습니다.
웹 스테이션
웹 기반 관리 / 모니터링 콘솔에서 매일 24 시간 어디서든 관리 할 수 있습니다.